并发
早期单线程 -> 时间切片 -> 快速任务切换 -> 并发模式
随着硬件的革新 -> 多核CPU -> 多任务执行 -> 并行
而并发模式的含义,也随着发现了一些转变,现在,我们把多个执行单位,对单一执行资源的竞争,叫做并发。
在竞争的过程中,为了确保不发生拥堵,我们需要引入调度机制。
所谓调度,实际上是对于任务按照某种机制进行排序,比如优先级,来达到插队、中断的效果。
前端开发过程中,很少能遇到并发的问题,出现就说明这是一个很复杂的场景,存在许多长耗时任务任务阻塞渲染
任务中断
js 函数执行的过程是不可中断,任一上下文的执行过程都是不可中断的。
实现可中断的方式只有一个:任务拆分 -> 循环/递归
任务 & 队列
递归的过程一定是在递归任务队列的。
react 中维护了两个队列:
- 临时队列
- 任务队列
任务队列中的任务 === 完整一次更新
通过 scheduleCallback 方法进行入队操作,实际上进入队列的函数就是 performWorkOnRootViaSchedulerTask,这个函数作用就是执行 fiber 节点的 diff 更新操作。
而 React 的一次更新,是从根节点开始,向下递归对比的过程。
// 声明一个状态
const [counter, setCounter] = useState(0);setCounter -> dispatchSetState -> ... -> scheduleCallback
set 方法可以看做任务触发器,它所对应的要执行的任务逻辑,是一次完整的更新过程。
set 之后调用链路:
dispatchSetState -> 「触发状态更新」
dispatchSetStateInternal -> 「将更新内容合并成 update 对象,挂载到 fiber 上」
scheduleUpdateOnFiber -> 「确定是否需要触发调度器进行状态更新」
ensureRootIsScheduled -> 「确保某个根节点的更新任务已经被调度,并会将更新任务推送到调度队列 - 通知根节点有一个更新产生」
scheduleImmediateTask ->
processRootScheduleInMicrotask ->
scheduleTaskForRootDuringMicrotask -> 「转换优先级」
scheduleCallback(schedulerPriorityLevel, schedulerPriorityLevel, performWorkOnRootViaSchedulerTask.bind(null, root)) -> 「将更新任务推送到任务队列 & 开始循环任务队列」
performWorkOnRoot -> renderRootSync -> workLoopSync / renderRootConcurrent -> workLoopConcurrent - 「循环 fiber 链表 diff 过程」ensureRootIsScheduled & 任务合并
一轮事件循环中,可能存在多个 setter 的调用,那么每一次 setter 对应一个完整的 diff 过程?
显然 react 不可能这么处理的。
// Used to prevent redundant mircotasks from being scheduled.
let didScheduleMicrotask: boolean = false;
if (!didScheduleMicrotask) {
didScheduleMicrotask = true;
scheduleImmediateTask(processRootScheduleInMicrotask);
}它在语义上的意思是确保根节点的更新任务被调度,通俗的说是通知根节点有更新,实际上在底层触发的一个 promise 任务。
核心作用在于合并多次更新,也就是批处理。
什么时候会被调用:
- 当组件调用 setState 或使用 hooks 进行状态更新时
- 当有新的 props 传入时
- 当 context 发生变化时
- 当有手势交互时(通过 scheduleGesture 函数)
- 当有过渡动画需要处理时
- 在事件处理完成后,需要更新 DOM 时
- 在批量更新结束时
setCounter()
setCounter()
setCounter()
setCounter()每一个 setCounter 最终对应的是一次自顶向下的完整的 diff 更新过程。如果不进行合并,会存巨大的性能问题。
因此在进入 taskQueue 「任务队列」之前还要进行合并。
setter x N -> microQueue -> taskqueue
为什么是微任务?
要合并多个 setCounter,则需要合并逻辑尽量在最后一个 setCounter 之后。前面都是进入队列进行收集等待。但是因为我们并不知道在一轮函数调用栈中,最后一个 setCounter 到底是哪一个。但是我们可以非常确定的知道,在事件循环中,微任务队列是在函数调用栈清空之后才开始执行的,所以这里是一个非常适合的时机。
每次 setter 之后执行 dispatchSetStateInternal,会把更新内容合并到 update 对象,最终挂载到 fiber 上。
批处理的核心就是,多次保存更新的数据,这些更新数据会组成一个链表,然后一次性统一处理。
总结
react 中,依赖于事件循环机制,也分别定义了自己的宏任务队列与微任务队列。利用微任务队列合并多次 ensureRootIsScheduled 的通知,从而减少了多次 diff 更新。
宏任务队列则是启动更新任务,其对应的是整个 diff 更新的渲染过程。
scheduleCallback
function unstable_scheduleCallback(
/* 任务优先级 */
priorityLevel: PriorityLevel,
/* 任务回调 */
callback: Callback,
options?: {delay: number},
): Task {
// ...
}任务入队 & 启动一轮循环。
在一轮循环中 scheduleCallback 中只会调用一次 schedulePerformWorkUntilDeadline。通过全局变量 isMessageLoopRunning 控制,开启循环之后可能还会入队任务。
调用链路
scheduleCallback -> 「将任务加入队列 & 开启循环队列」 requestHostCallback -> schedulePerformWorkUntilDeadline -> 「类似settimeout(performWorkUntilDeadline, 0),开启循环」 performWorkUntilDeadline -> flushwork -> workloop 「开始递归任务」
function requestHostCallback() {
/* 是否已经开始循环任务 */
if (!isMessageLoopRunning) {
isMessageLoopRunning = true;
/* 对定时器的封装 */
schedulePerformWorkUntilDeadline();
}
}
/* 类似 settimeout(performWorkUntilDeadline, 0) -> 宏任务中开始循环任务队列 */
let schedulePerformWorkUntilDeadline;
if (typeof localSetImmediate === 'function') {
// Node.js 或者 老版本的 IE
schedulePerformWorkUntilDeadline = () => {
localSetImmediate(performWorkUntilDeadline);
};
} else if (typeof MessageChannel !== 'undefined') {
// DOM and Worker environments.
// We prefer MessageChannel because of the 4ms setTimeout clamping.
const channel = new MessageChannel();
const port = channel.port2;
channel.port1.onmessage = performWorkUntilDeadline;
schedulePerformWorkUntilDeadline = () => {
port.postMessage(null);
};
} else {
schedulePerformWorkUntilDeadline = () => {
localSetTimeout(performWorkUntilDeadline, 0);
};
}
/* flushwork -> workloop -> while taskQueue */
const performWorkUntilDeadline = () => {
if (isMessageLoopRunning) {
const currentTime = getCurrentTime();
/* 记录循环开始时间 */
startTime = currentTime;
let hasMoreWork = true;
try {
/* 循环过程可能还在调用 scheduleCallback push 任务 */
hasMoreWork = flushWork(currentTime);
} finally {
if (hasMoreWork) {
/* 还有任务继续循环 */
schedulePerformWorkUntilDeadline();
} else {
isMessageLoopRunning = false;
}
}
}
};schedulePerformWorkUntilDeadline
schedulePerformWorkUntilDeadline -> performWorkUntilDeadline
类似与 settimeout(performWorkUntilDeadline, 0),启动宏任务开启循环任务队列,performWorkUntilDeadline 会调用 flushwork & workloop 函数,来遍历 task-queue。
schedulePerformWorkUntilDeadline 是开启宏任务,每次执行会加入到宏任务队列,在下一事件循环中执行。
注意 performWorkUntilDeadline 可能被中断,然后重新递归调用 schedulePerformWorkUntilDeadline,继续循环。
schedulePerformWorkUntilDeadline -> performWorkUntilDeadline -> yield -> schedulePerformWorkUntilDeadline
workLoop
循环任务队列,执行任务回调,任务来自于 scheduleCallback(performWorkOnRootViaSchedulerTask)。
performWorkOnRootViaSchedulerTask -> performWorkOnRoot -> renderRootConcurrent -> workLoopConcurrent
workLoopConcurrent 实际上就是在循环 fiber 链表
function workLoop(initialTime: number) {
let currentTime = initialTime;
/* 遍历临时队列 timerQueue */
advanceTimers(currentTime);
/* 取堆顶任务 */
currentTask = peek(taskQueue);
while (currentTask !== null) {
/* 检查是否需要让出主线程 */
if (!enableAlwaysYieldScheduler) {
if (currentTask.expirationTime > currentTime && shouldYieldToHost()) {
break;
}
}
// 执行回调
const callback = currentTask.callback;
if (typeof callback === 'function') {
currentTask.callback = null;
currentPriorityLevel = currentTask.priorityLevel;
const didUserCallbackTimeout = currentTask.expirationTime <= currentTime;
/**
* 执行任务回调
* 这里的返回值实际上也是 callback,是因为在循环 fiber 链表的过程也可能会中断,所以这里需要记录下来,等待下一次执行
*/
const continuationCallback = callback(didUserCallbackTimeout);
// 处理任务结果
if (typeof continuationCallback === 'function') {
currentTask.callback = continuationCallback;
return true; // 还有工作要做 - 重新入队
}
}
/* 处理下一个任务 */
currentTask = peek(taskQueue);
}
// 返回是否还有剩余任务
return currentTask !== null;
}
/**
* 1. 清理掉被取消的延迟任务
* 2. 将符合执行条件的任务换个优先级队列 timerQueue -> taskQueue
*/
function advanceTimers(currentTime: number) {
// Check for tasks that are no longer delayed and add them to the queue.
let timer = peek(timerQueue);
while (timer !== null) {
/* 移除已取消的任务 */
if (timer.callback === null) {
pop(timerQueue);
} else if (timer.startTime <= currentTime) {
// Timer fired. Transfer to the task queue.
pop(timerQueue);
timer.sortIndex = timer.expirationTime;
push(taskQueue, timer);
if (enableProfiling) {
markTaskStart(timer, currentTime);
timer.isQueued = true;
}
} else {
// Remaining timers are pending.
return;
}
timer = peek(timerQueue);
}
}时间切片
React 基于事件循环实现了
- 微任务 scheduleImmediateTask 合并多个更新触发
- 宏任务 scheduleCallback 启动 taskQueue 队列
微任务层面实际上不受 react 控制,所以只能在宏任务「taskQueue」中实现时间切片。
其中 shouldYield 就是中断条件。
shouldYield
react 内部循环中断条件,判断当前一轮循环是否超过一帧「react 内部定义帧 - frameInterval」
/* React 内部维护的任务队列开始循环的时间 */
let startTime = -1;
function shouldYieldToHost(): boolean {
const timeElapsed = getCurrentTime() - startTime;
/* frameInterval - 内部一帧的时间「默认 5ms」时间切片 */
if (timeElapsed < frameInterval) {
return false;
}
return true;
}外层循环 - schedulePerformWorkUntilDeadline
外层通过递归调用 schedulePerformWorkUntilDeadline,来启动 flushWork -> workLoop。
const performWorkUntilDeadline = () => {
if (isMessageLoopRunning) {
const currentTime = getCurrentTime();
startTime = currentTime;
let hasMoreWork = true;
try {
/* 是否还有剩余任务 */
hasMoreWork = flushWork(currentTime);
} finally {
if (hasMoreWork) {
/* 继续递归 - settimeout 下一次事件循环,如此就可以让有些任务实现插队 */
schedulePerformWorkUntilDeadline();
} else {
isMessageLoopRunning = false;
}
}
}
};schedulePerformWorkUntilDeadline -> performWorkUntilDeadline -> flushWork -> workLoop --{maybe shouldYield}-> schedulePerformWorkUntilDeadline
flushWork -> workLoop 可能存在中断,会返回是否还有剩余任务标识,存在剩余任务则继续递归调用 schedulePerformWorkUntilDeadline
宏任务队列中的任务在执行过程中,如果产生了新的任务,会推入到临时队列中由下一轮事件循环执行。
因此,新的更新任务 setXxxx 便有了插队的可能性。只要优先级够高,就可以在进入优先级队列时排在前面。在下一轮宏任务队列遍历时优先执行。
内层循环 - workLoop
workLoop实际上就是在循环任务队列,会通过 peek 取出堆顶任务,然后执行其中存储的 callback 回调。
值得注意的是:callback 的执行也可能会被中断,只执行了一部分,所以他会把剩下的任务记录下来并返回,重新入队,等待在一下轮事件循环中继续执行。
callback 单任务内部实际上就是 fiber 链表 的循环。
总结
整个时间切片的实现原理,我们要结合浏览器的事件循环机制才能完整的消化这一部分逻辑。在源码逻辑上一共有三层循环,外层的递归循环,内层的 taskQueue workLoop,以及单个任务的 FiberTree workLoopConcurrent。
优先级
存在多个优先级,且存在转换关系。
Lane -> EventPriority -> PriorityLevel -> expirationTime -> sortIndex
Lane、EventPriority 都是 LaneLevel
expirationTime、sortIndex 都是 TimerLevelPriorityLevel
export type PriorityLevel = 0 | 1 | 2 | 3 | 4 | 5;
// TODO: Use symbols?
export const NoPriority = 0;
// 立即执行,优先级提前、可用于模拟微任务的执行时机
export const ImmediatePriority = 1;
// 通常指输入、用户点击等影响用户体验的响应事件触发的更新,优先级较高
export const UserBlockingPriority = 2;
// 普通更新优先级,大多数的状态更新都是这个级别
export const NormalPriority = 3;
// 低优先级
export const LowPriority = 4;
// 空闲优先级,优先级最低,startTransition 会使用这个优先级
export const IdlePriority = 5;基本会在入队scheduleCallback的时候跟随任务一起传递。
// useEffect 的更新
scheduleCallback(NormalSchedulerPriority, () => {
flushPassiveEffects(true);
// This render triggered passive effects: release the root cache pool
// *after* passive effects fire to avoid freeing a cache pool that may
// be referenced by a node in the tree (HostRoot, Cache boundary etc)
return null;
});
// startTransition
if (prevPendingTransitionCallbacks !== null) {
currentPendingTransitionCallbacks = null;
scheduleCallback(IdleSchedulerPriority, () => {
processTransitionCallbacks(
prevPendingTransitionCallbacks,
endTime,
prevRootTransitionCallbacks,
);
});
}TimerLevel
在入队的时候,会根据优先级去固定推算过期时间「expirationTime」,然后队列会根据这个字段进行排序。
var expirationTime = startTime + timeout;
/* 顶堆中的排序函数 */
function compare(a: Node, b: Node) {
/* sortIndex == expirationTime */
const diff = a.sortIndex - b.sortIndex;
return diff !== 0 ? diff : a.id - b.id;
}所以需要注意的是:优先级高的 !== 先执行
最终任务队列还是根据 expirationTime 进行排序的,然而 expirationTime 还有一个因素是 startTime,也就是入队的时间。
因此,进入队列得越早,那么执行的优先级也会越高。
LaneLevel
Lane 专门用来管理 Fiber 节点的优先级。Fiber 节点任务比较细,所以我们需要一种机制来管理这些细粒度的优先级。
在调用 scheduleCallback 前会通过 scheduleTaskForRootDuringMicrotask 将 lane 转为 PriorityLevel。
scheduleTaskForRootDuringMicrotask -> scheduleCallback
// 转换优先级
function scheduleTaskForRootDuringMicrotask(
root: FiberRoot,
currentTime: number,
): Lane {
...
const nextLanes = getNextLanes(
root,
root === workInProgressRoot ? workInProgressRootRenderLanes : NoLanes,
);
let schedulerPriorityLevel;
switch (lanesToEventPriority(nextLanes)) {
case DiscreteEventPriority:
schedulerPriorityLevel = ImmediateSchedulerPriority;
break;
case ContinuousEventPriority:
schedulerPriorityLevel = UserBlockingSchedulerPriority;
break;
case DefaultEventPriority:
schedulerPriorityLevel = NormalSchedulerPriority;
break;
case IdleEventPriority:
schedulerPriorityLevel = IdleSchedulerPriority;
break;
default:
schedulerPriorityLevel = NormalSchedulerPriority;
break;
}
const newCallbackNode = scheduleCallback(
schedulerPriorityLevel,
performWorkOnRootViaSchedulerTask.bind(null, root),
);
root.callbackPriority = newCallbackPriority;
root.callbackNode = newCallbackNode;
return newCallbackPriority;
}为了更快的运算速度,React 底层基于 31 位二进制的位运算来设计 Lane 的优先级模型。
通过 |「按位或-合并」、&「按位与-检查」、~「按位反-删除」来实现优先级的操作。
fiber
fiber 是 React 的工作单元,每个组件都有一个对应的 fiber 节点。
在 fiber 之前,react 中存在三种节点对象。
- VisualDom
- ReactElement
- fiber
jsx -> ReactElement「静态节点」 -> fiber「包含动态内容,存储状态、更新、链表」 -> VisualDom
fiber-tree 构建
fiber tree 在构建的过程中「深度优先遍历」,会交替执行 beginWork、completeWork。
fiber 树构造循环负责构造新的 fiber 树, 构造过程中同时标记 fiber.flags, 最终把所有被标记的 fiber 节点收集到一个副作用队列中, 这个副作用队列被挂载到根节点上 (rootFiber.alternate.firstEffect). 此时的 fiber 树和与之对应的 DOM 节点都还在内存当中, 等待 commitRoot 阶段进行渲染。
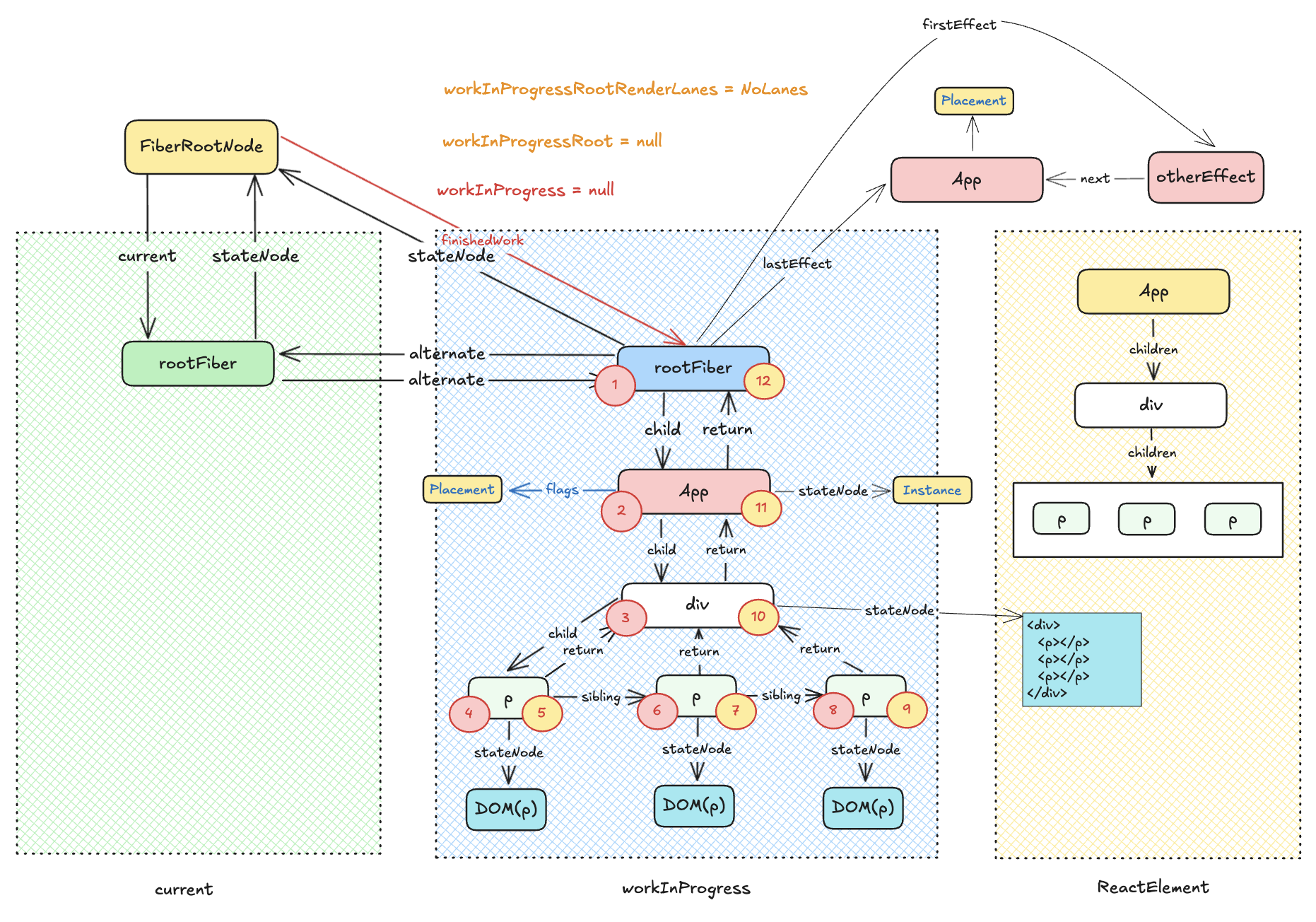
executionContext
用于描述当前的执行上下文。执行上下文会记录当前的任务执行阶段,例如是否处于渲染阶段。
/* ReactFiberWorkLoop.js */
type ExecutionContext = number;
// 没有上下文
export const NoContext = /* */ 0b000;
// 批处理阶段
const BatchedContext = /* */ 0b001;
// 渲染阶段
export const RenderContext = /* */ 0b010;
// 提交阶段
export const CommitContext = /* */ 0b100;
// Describes where we are in the React execution stack
let executionContext: ExecutionContext = NoContext;
// 在其他模块获取当前上下文
export function getExecutionContext(): ExecutionContext {
return executionContext;
}例如在 scheduleImmediateTask 中就会取该状态判断,处于渲染或提交阶段,则触发任务队列入队,并标记高优先级。
lanes
任务优先级,在 react 中存在三种 lanes。
- update.lanes - 表示当前 update 的优先级通道(lane)
- fiber.lanes - 表示该 fiber(节点)上挂载了哪些优先级的更新
- render.lens - 当前一次 render 使用的 lanes(优先级通道集合)
update 是一个挂载在 fiber.updateQueue 上的更新对象,记录了 setState 的 action 内容、优先级等。
三者关系:
setState() 触发 -> 生成 update.lane
|
V
update 被挂载到 fiber.updateQueue
|
V
fiber.lanes |= update.lane
|
V
markUpdateLaneFromFiberToRoot()
|
V
root.pendingLanes |= update.lane
|
↓ 调度 ↓ 进入 render
|
V
renderLanes = getNextLanes()update.lanes --合并-> fiber.lanes --合并-> root.paddingLanes
在渲染时,只处理 fiber.lanes & renderLanes 的节点。
diff
diff 中的一段逻辑
- props 是否发生了变化
- context 是否发生了变化
- 继续判断是否有挂起的 update 或者 context
- 继续判断是否存在捕获到的错误标记
这些都没有发生之后,才会最终决定复用节点,否则就会重新创建节点。
context 优化 -「React-19」
React 的 Context 是一种用于跨组件树传递数据的机制。当一个 Context 的值发生变化时,React 会通知所有订阅了该 Context 的组件重新渲染。然而,这种机制在某些情况下可能会导致性能问题:
不必要的渲染:即使某个组件并不直接使用 Context 的值,只要它的父组件订阅了 Context,它也会被重新渲染。
高频更新:如果 Context 的值频繁变化,可能会导致大量组件重新渲染,影响性能。
为了解决这些问题,React 引入了 懒传播机制。
Lazy Context Propagation
懒传播的核心思想是:只有当组件真正使用了 Context 的值时,才通知它重新渲染。这样可以避免不必要的渲染,提高性能。
- 优化 Context 的性能,减少不必要的渲染。
- 在并发模式下更好地支持高频更新和复杂依赖关系。
- 提供更细粒度的更新控制
hook
class 组件存在的问题
类组件的开发方式非常直观和易于理解。
但状态和组件是紧密耦合在一起的,需要复用某一段逻辑的时候就很复杂,得通过高阶组件的方式去做。
然而 class 高阶组件会产生一些问题:
- 代码冗余不简洁,可读性低
- 远超预期的组件嵌套层级
- 复用多段状态逻辑时,无法在组件中区分来源,并且同名的状态会冲突
hook & 闭包
所有 hook 都有一些特性:数据缓存。
实际是组件本身也就是一个函数,在 react 底层组件函数外层实际还会套函数。
那么要缓存函数内部的状态,最佳的途径就是 闭包。
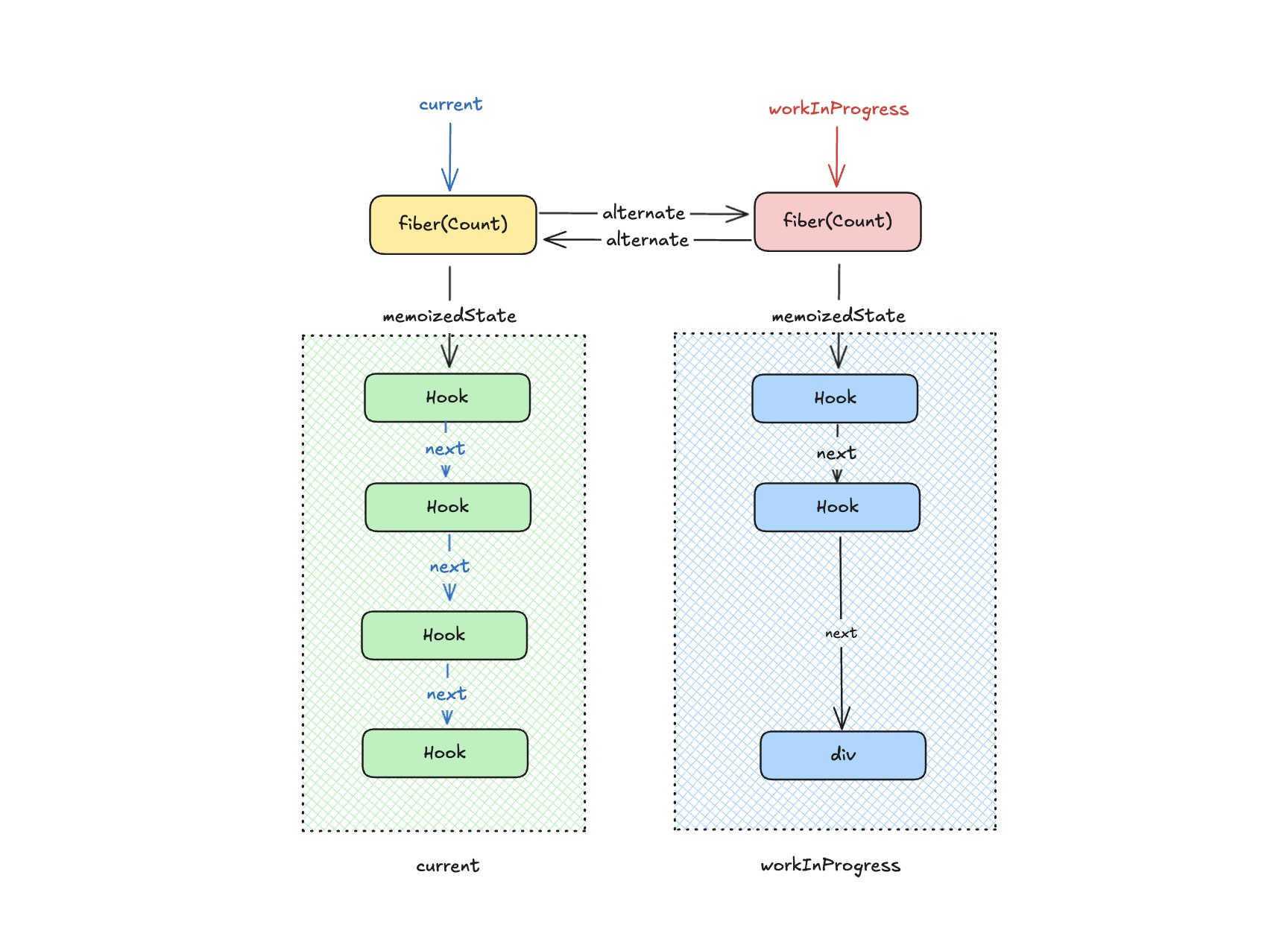
fiber 与 hook 之间,既要能够各自独立,又要能够相互关联。而要做到这个事情,我们可以利用闭包来实现。
Comp -> fiber -> fiber.memoizedState
每个组件的 hook 是通过链表的形式存储在 fiber.memoizedState 上的。
Hook & fiber
组件函数在执行的过程中,会执行 hook,例如 useState。此时会创建 hook 对象,并挂在到 fiber 实例上。
执行组件函数「Component」发生在:
beginWork -> updateFunctionComponent -> renderWithWork -> Component()
Hook 的类型定义:
// 「state-hook」
export type Hook = {
// 当前 hook 的状态值
memoizedState: any,
// 基准值 - 每次 update 的基准
baseState: any,
// 存储 高于本次渲染的 update 环形链表
baseQueue: Update<any, any> | null,
// update 循环链表
queue: any,
// 指向下一个 hook
next: Hook | null,
};
// 「effect-hook」
type EffectInstance = {
destroy: void | (() => void),
};
export type Effect = {
// effect 类型
tag: HookFlags,
// 副作用回调
create: () => (() => void) | void,
// 副作用清理函数
inst: EffectInstance,
// 依赖项
deps: Array<mixed> | null,
// 指向下一个 effect
next: Effect,
};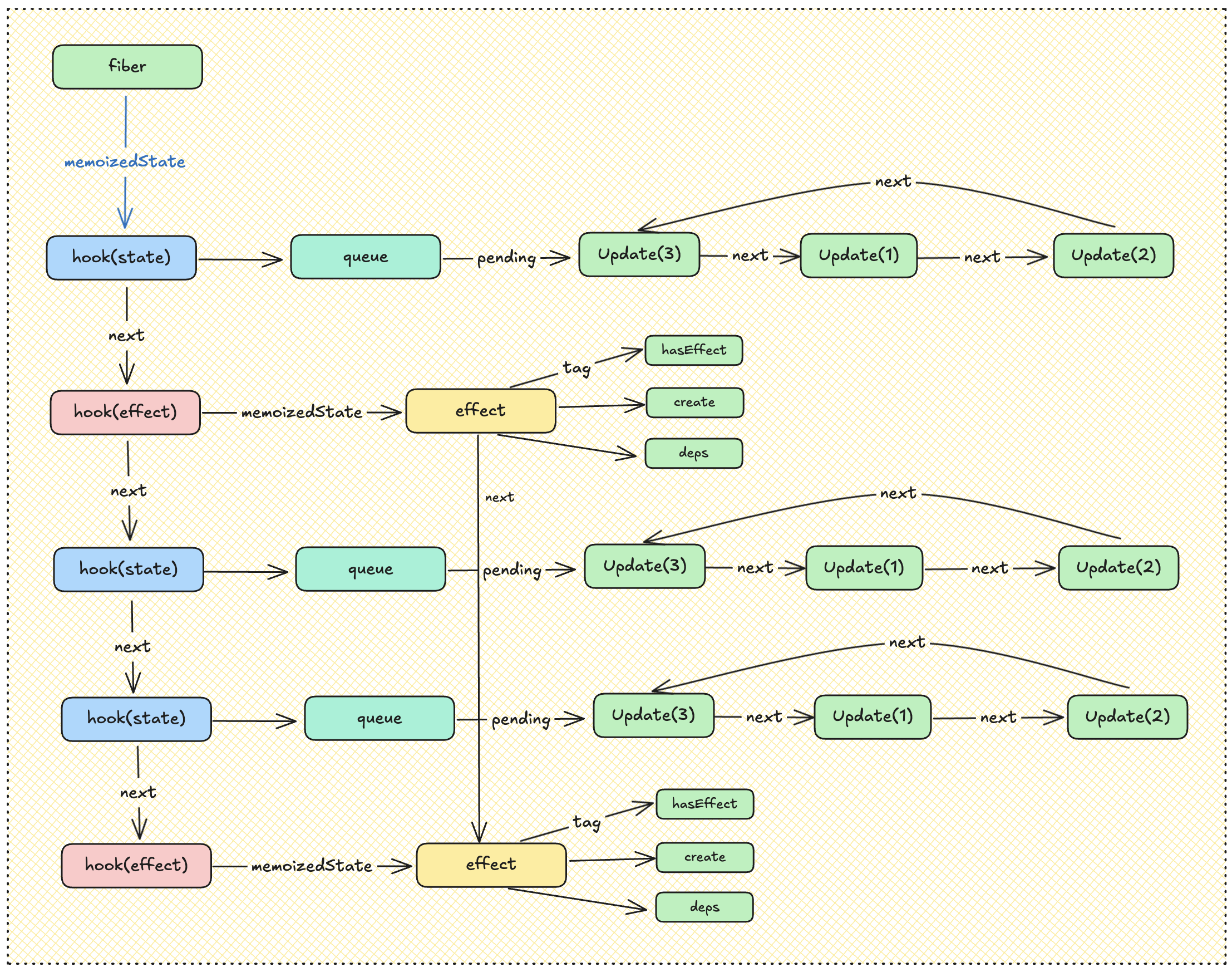
renderWithHooks
├── mountState / updateState(构造 useState)
├── mountEffect / updateEffect(构造 useEffect)
└── 构建 Hook 链表(memoizedState 单向 + effect 环形)
setState / dispatch
└── 添加 update 到 pending 环形链表,调度更新
commitRoot
└── 遍历 updateQueue.lastEffect(effect 环形链表),执行副作用后续...
Diff 架构
React 更新机制
主流数据驱动 UI 方案:
- 颗粒度更新 - 数据劫持
- 全量更新
所有的事情都是对等的。
颗粒度更新,能快速的在数据发生变化的时候,以最小的代价更新 dom,代价就是在初期需要通过Proxy做数据劫持,将数据与视图绑定,这一过程必然是额外耗时的。遇到越复杂嵌套的数据结构,劫持的过程就会越复杂。
全量更新,则是自顶向下,将页面所有的函数全部执行一遍,当然在整个过程中有 diff 算法的优化。
全量更新的优势:
- 数据干净,不需要额外的处理,在复杂数据的处理场景下有明显的优势
- 符合函数式的编程思想,在代码的开发体验、执行的可预测性上有明显的优势。因此,React 组件更容易被测试,在可维护性上有明显的优势
缺点就是不能全靠 diff 算法做到高效的颗粒度更新,更多的需要开发者自行配合。
diff 策略
核心策略:同层比较
dom 节点中移动的情况是很难去把控的,比如说某一个节点加到某个节点下面,作为子节点,那到底是移动、还是创建了父节点,很难去判定。
因此,react 中放弃了移动的情况,采用了同层比较。
需要注意的是列表节点还是会考虑移动的情况的。
因为整个列表重新构建可能存在更大的内存消耗,相对于移动来说,并且列表中的移动相对来说是很好判断。
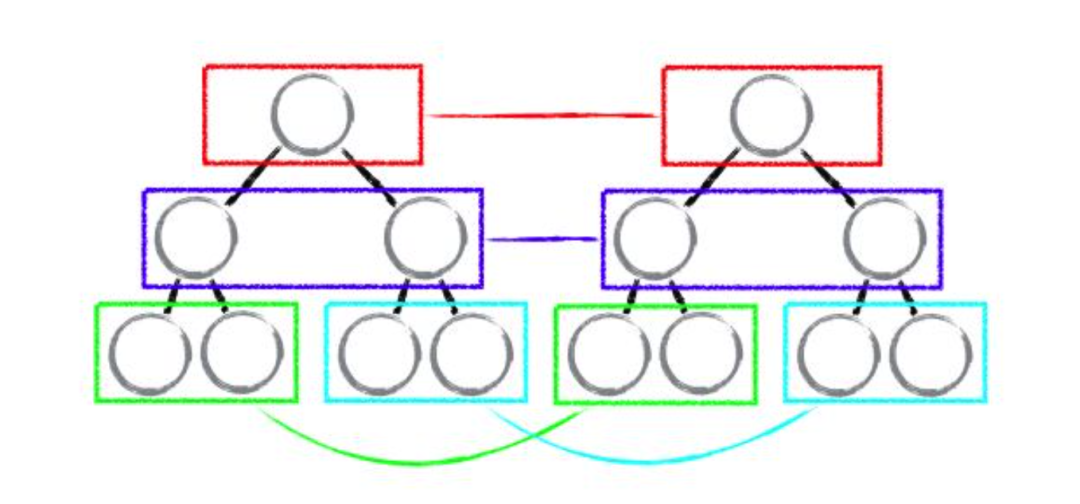
节点复用
核心是通过 didReceiveUpdate「全局变量」 来标记当前节点是否能够复用。
- props
- context
- 通过优先级判断是否符合复用条件
- state
节点比较
workLoopConcurrent -> performUnitOfWork -> beginWork
beginWork 中则是根据 props/context/state 去变更 didReceiveUpdate 的值,来确定子节点是否可以复用。
workLoopConcurrent 传入的 workInProcess 是当前工作中的根节点,因此实际上每轮比较的节点是子节点,而不是当前节点。
当前 fiber 节点确定无法复用后,会通过 reconcileChildFibers 进一步判断子节点是否能够复用。
因为一旦 fiber 节点不可复用,react 会将其包括其子节点全部重新构建,此时就需要尽可能的复用其子节点。
其内部会根据节点类型调用一下函数:
function reconcileSingleElement() {...}
function reconcileSingleTextNode() {...}
function reconcileChildrenIterator() {...}
function reconcileChildrenIteratable() {...}
function reconcileSinglePortal() {...}
function reconcileChildrenArray() {...}列表节点
相对于原来节点位置移动到后面的时候,才会移动节点。
这里说的移动,指的是对真实 dom 的操作。
旧列表:[A] [B] [C] [D]
新列表:[B] [A] [D] [C]
[B] 不移动
[A] 相对后移了,移动
[C] 相对后移了,移动
[D]不移动事件系统
JSX 不是真实的 DOM,因此上面的事件也不是直接 DOM 上的原生触发的事件。
React 并不会为每个组件或 DOM 节点都绑定事件。
React 中是通过 统一的事件监听器 挂在根节点上,然后在事件触发时,使用一套自己的“合成事件系统”进行处理。
在 fiber-tree 构建的时候,事件回调存储在 fiber 节点中,并且将事件注册在根节点上。
dom 触发事件的时候,根据 target 找到对应的 fiber,并且向上冒泡,执行事件回调。
整个过程中,react 自己合成了事件对象,也就是通常回调接收的参数 event。
通过合成来实现跨浏览器兼容、性能优化和统一的事件管理。
JSX 中写 onClick
↓
Fiber 构建时写入 memoizedProps
↓
首次渲染注册 document 上的 click 事件监听器
↓
浏览器原生事件冒泡到 container
↓
React 捕获 → 找到事件 target 对应的 Fiber 节点
↓
查找回调 → 封装 SyntheticEvent
↓
依照冒泡/捕获阶段顺序执行事件函数 - 「从当前节点向上寻找相同事件」Sum
为什么 React 内部要自定义帧,不直接使用浏览器已经存在的刷新率呢?或者会问为什么不直接基于 requestIdleCallback 来实现剩余逻辑的执行?
这里核心的原因是为了兼顾不同平台的特性。在浏览器之外的其他场景,可能并不支持刷新率相关的事件回调。
React 同步更新模式与异步更新模式的区别?
同步模式中,不会对任务进行优先级的设计与调度,有一个任务产生就会直接执行,不会按照时间切片中断任务的执行,因此有阻塞页面渲染的风险,可能会造成页面卡顿。
为什么不能把 Hook 写在条件渲染中?
「react hook 是存储在链表的数据结构中的,if 条件会导致链表节点缺失」
这是因为我们在函数运行过程中,访问 hook 是通过 current.memoizedState 访问,其对应的是 hook 链表,然后通过 currentHook.next 来访问下一个 hook
如果我们将 hook 放入条件判断中,那么在不满足条件时,该 hook 对象就不会在链表中存在,从而导致两次访问到的 hook 不一致,从而造成取值错误
[完结🎉]
受益匪浅,但有些地方理解不是很透彻,后续有空要重头再过过。
原内容来自波佬的useHook-React面试原理,强烈推荐购买阅读。